-
友情链接:
OpenAI断供,中国企业:谢邀,已登顶
- 发布日期:2024-07-01 23:17 点击次数:211
OpenAI断供了。
自7月9日起,包括中国大陆、中国香港、俄罗斯、朝鲜、伊朗等国家和地区都不能再接入他们的API。
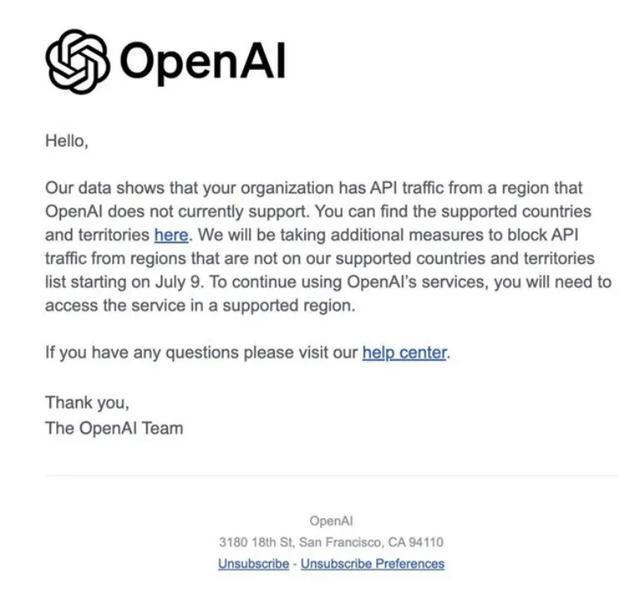
一看名单,全是美利坚的制裁对象,这当然是一个政治问题。
不过大家要是对OpenAI这家公司持续关注的话,这个决定一点也不奇怪。
不久前,OpenAI的CEO奥特曼就解散了安全团队——超级对齐,这个由OpenAI曾经的首席科学家Ilya Sutskever带的团队。

Ilya随即出走。很快,奥特曼就组建了一个新的安全团队,而这个团队的领导人是美国国安局前局长保罗·中曾根(Paul M. Nakasone)。

当OpenAI变成CloseAI,会对整个行业带来什么影响呢?
我们先看看这一波“断供”可能会带来什么吧。
01
所谓的断供“API”,这里的API指的是“应用程序编程接口”。
你可以把API通俗地理解为餐厅的菜单。你可以用它来点菜,但你并不知道菜是怎么做出来的。
还记得ChatGPT刚出来那阵儿,涌现出来无数AI公司么。它们就是顾客,炒菜的是OpenAI,然后它们再把炒好的菜包装一下,卖给餐厅外的我们。
所以本质上它们就是套壳公司,真正生产的是OpenAI。
可想而知,断供对这些公司来说无异于釜底抽薪,把吃饭的家伙给收走了。
但换个角度想,OpenAI这个AI行业内巨无霸居然主动让出市场,有钱不赚是傻蛋。
这不,国内各路高手立马就像饿虎扑食一样冲上来抢这泼天富贵,各种“搬家计划”纷纷出炉,服务不要太周到。
比如阿里的通义千问,除了提供专属的迁移服务外,主力模型调用API的价格更是只有GPT-4的1/50。这还是在通义千问跟GPT-4实力相当的情况下的价格。
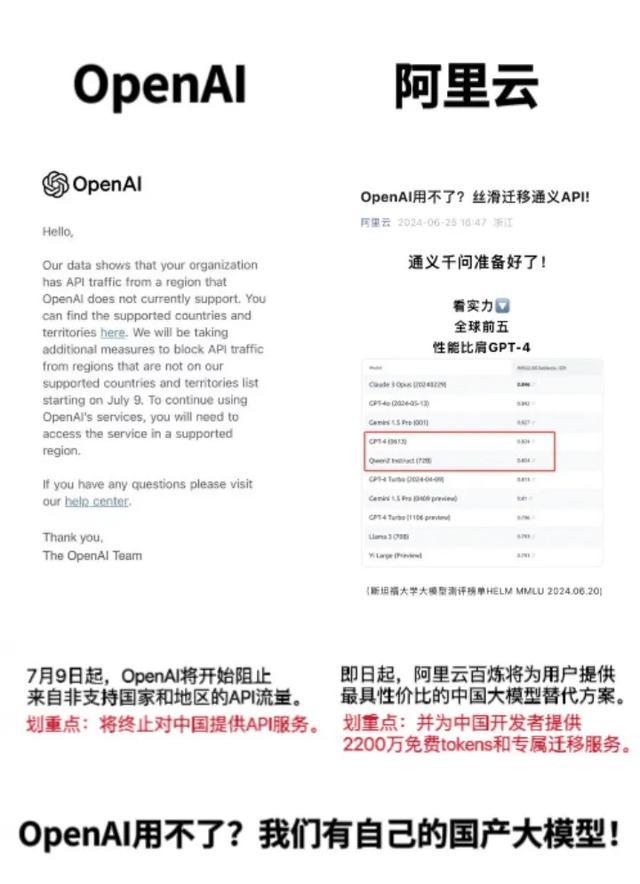
其他包括智谱、讯飞、百度、百川等都提供了相当优惠的价格。
所以,现在摆在他们面前的已经不是to be or not to be的生死问题,而是如何从一众“备胎”中挑最好的那个。
02
什么样的模型才是好模型呢?
正如欧洲历史上最强的男人拿破仑所说,不想拿第一的模型不是好模型。

就像学生通过各个科目的考试比成绩,大模型的能力也是看做题的成绩。
学生有语数外理综文综的项目,大模型有推理能力、数学能力、编程能力、语言能力、多模态能力等多种项目。
比如最常用的MMLU数据集,内容涵盖了STEM、人文、社科等57个学科,就是常用来测试模型知识和推理能力的数据集。
此外还有专考中文的C-Eval、考奥数的MATH(好会取名字)等等。
自然,每家模型都会争取考个好成绩。但就像学生考试一样,有的人实力强大,有的人有自己的办法。
截至2024年6月28日,C-Eval榜单上,前20名全是我国的大模型,GPT-4位于21位。
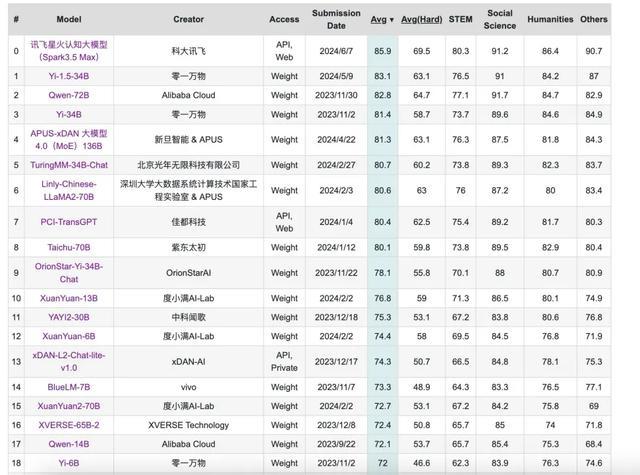
这并不符合我的实际体验,虽然GPT-4的能力并没有像以前一样碾压了,但也不至于排到21名啊。可以说,这份榜单在某种程度上失真了。
造成这种现象的原因有很多。
首先是随着大模型的不断升级,一些题目变得相对简单了。就像以前大家都是小学生,考初中的题目,大家分都不高。但经过一年多的学习,大家的水平上升到了高中生,再去做这些题,都能得个90分以上,那么这个试题就不能很好地区分大家的水平了。
其次,闭卷变开卷。虽然这些考题都不是公开数据集,但我每天就搁那考试,一连考几十天。那考试就跟刷题库一样了,考试的题目也逐渐公开。后来的大模型们直接用这些公开的题目去训练,那再去考的时候,就相当于开卷考试了。就算是难如数学竞赛,出成绩也不是不可能的。
当然了,考题本身的质量也很重要。
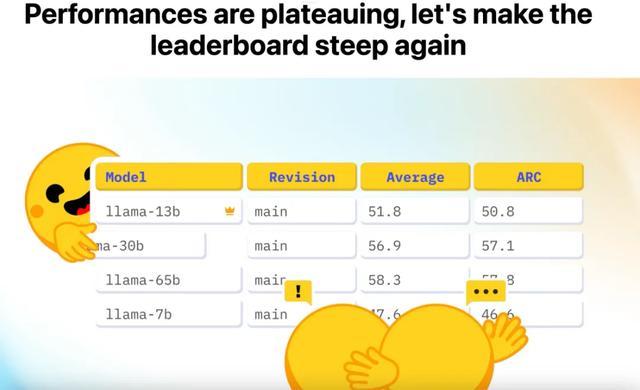
这是著名的开源社区Huggingface发布的榜单Open LLM Leaderboard的最高成绩。可以看到,从2023年9月到2024年5月,大模型在各个科目取得的成绩都不断地提高,都接近虚线,也就是人类水平。

当然这个成绩并不意味着大模型已经跟人一样了,而是说明了这份卷子已经被做烂了。
所以,Huggingface在6月推出了一套新试题,升级版的Open LLM Leaderboard v2。
这套试题比此前版本难度高了不少,比如GPQA数据里面全是研究生级别的知识,且专门找了生物、物理、化学等领域的博士生来出题。
客观讲,这一波很有诚意,没给那些刷榜的大模型留下什么空子钻。
各考生做这套卷子的成绩很快出来,榜单很出乎意料:
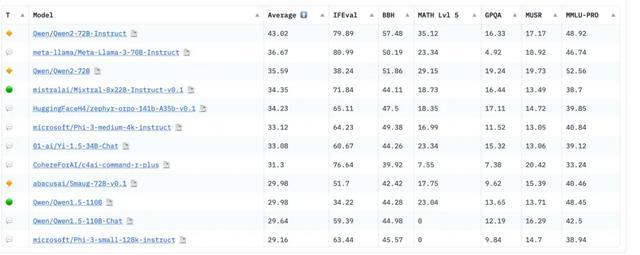
里面有不少老熟人,当红炸子鸡,“法国的OpenAI”Mistral、“史上最强开源大模型”Llama3以及打败了Llama3的通义千问Qwen2-72B(720亿参数)。
在这家法国榜单上看到咱国产的通义千问,属实是有点惊讶。

我又去看了详细的成绩单,Qwen2的数学(MATH)、专业知识(GPQA)和长上下文推理(MuSR)是优势学科,尤其是数学,比第二高了6分。哦不好意思,第二名是没有经过微调的Qwen2。
这份成绩得到了Huggingface CEO的称赞:
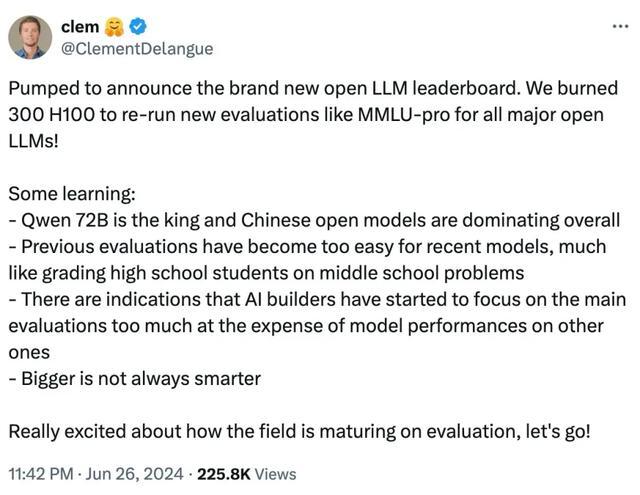
我去看了另一个榜单LiveBench AI,这是在图灵奖得主、AI三巨头之一的杨立昆(Yann LeCun)主导的一个大模型测评基准。
Qwen2-72B排名第8。
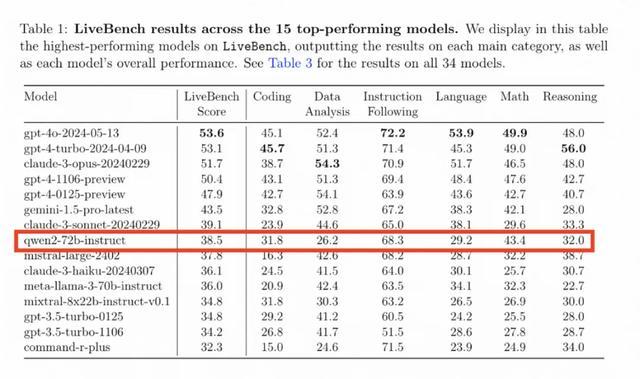
但这是包括了所有闭源模型的总榜单,Qwen2-72B是前十中唯一一个开源模型。
还有其他的榜单,Qwen2基本都是开源中的霸主,在这里就不多列了。
这说明了Qwen2的做题能力很强。但它到底是做题家还是真的实力强大呢?这需要一线开发者的测试。
红迪(reddit)里的开发者测试后,给出了肯定的评价:

初次测试很不错,有一个题目其他模型都错了,只有Qwen7B对了
另一个意大利的开发者甚至说“太强了以至于不像真的”:
我又去看了看推特,开发者们测试后也都非常认可Qwen2的能力,比如这位斯坦福的计算机副教授Percy Liang:
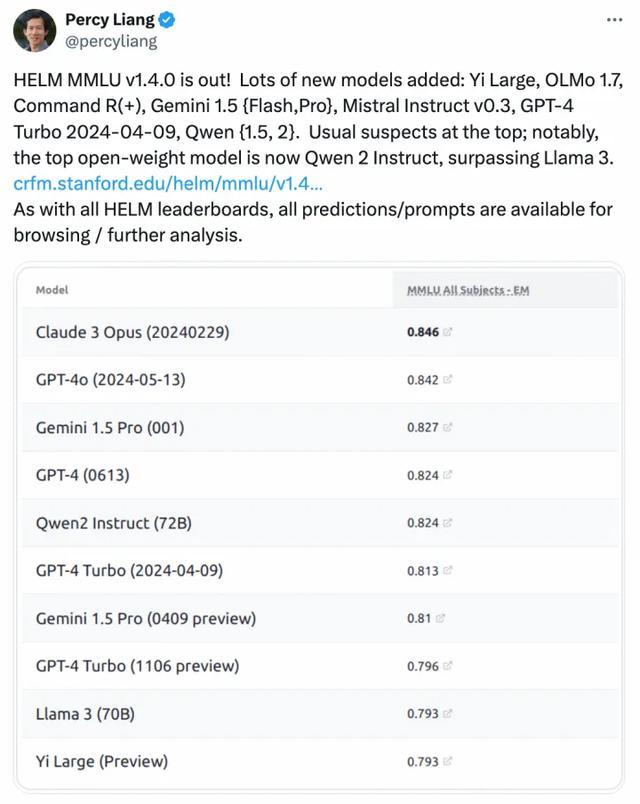
至此,我觉得Qwen2的实力已经没什么可质疑的了。
03
开源这条赛道上,竞争从来都不比闭源小。
前有法国独角兽Mistral直接免费甩出自家大模型 Mistral 7B 的磁力下载链接。
开发者们下下来一跑,发现竟然性能并不比 130 亿参数的 Llama 2 弱多少,而且微调一下,用一张显卡上就能跑。
后来他们又推出了更大参数量的 Mixtral 8x7B,性能追平了Llama2和ChatGPT3.5。
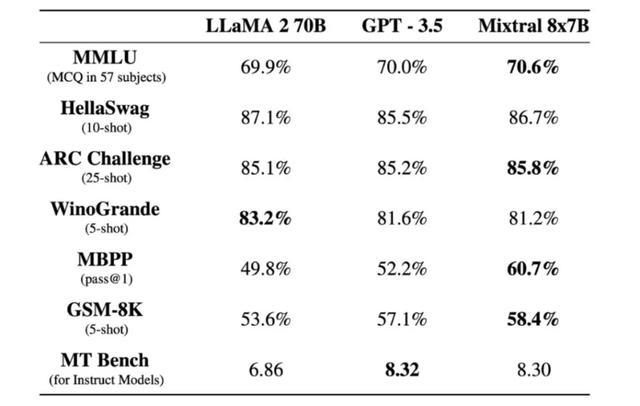
这让Mistral先后融资超11亿刀,数钱数到手软。
而两个月前,深耕开源的Meta正式发布了Llama3 8B和70B,这个据估计花费了1500万美元来训练的开源模型,重新夺回铁王座。

Meta官方认证为“迄今为止最强的开源大模型”。
当时外界有一种声音说:“只有GPT-5能压住Llama3了。”
但GPT-5没来,Qwen2先来了,惊不惊喜,意不意外?

其实,阿里云是国内首个做开源的大型科技企业。2023年8月,他们就开源了Qwen7B。
到现在,他们一共开源了Qwen-VL、Qwen-14B、Qwen-72B、Qwen-1.8B、Qwen-Audio、Qwen1.5的8款模型和Qwen2系列的5个模型,参数从5000万到720亿,可谓是全家桶了。
看到这里,可能有人会问,阿里云还有自己的闭源模型,是在开源上迟疑了吗?
但Qwen2这次全球第一的“出人头地”,证明了阿里云做开源是认真的!
随着GPT-5发布时间一而再再而三地延后,现在的消息已经推迟到明年年底了,大概率OpenAI还没找到办法让GPT-5在GPT-4的基础上大幅进步。
而与此同时,以Qwen2为代表的开源模型,表现正不断地逼近闭源模型之首GPT-4。
将OpenAI变为CloseAI,从非盈利变为盈利的Sam Altman,在看到Qwen2的表现时,是否心中会生出一丝后悔呢?
相关资讯
-
周慧敏宣布不再开个人大型演唱会,要照顾自己、家庭和猫
- 关于新航注册 2024-09-09
- 红星新闻消息,日前,“玉女掌门人”周慧敏在澳门举行“地老天荒爱一场”巡回演唱会。9月2日,通过周慧敏发出的视频中可以看到,她在演出时,突然宣布完成这次巡演后,将不会再做个人大型演唱会。 \n 周慧敏说:“因为在上一个巡演中,我经常会讲到,人...
-
[小炮APP]北单情报:SBV精英21场均有失球 防守糟糕
- 关于新航注册 2024-08-23
- SBV精英(主队) 有利情报 1. SBV精英成立于1902年,位于荷兰鹿特丹,球队主场为伍德斯坦球场。球队历史上获得过3次荷乙联赛冠军。 2. SBV精英比赛球不少,近34场正赛至少2球,近11场更是全部3球起步。 3. SBV精英近30...
-
皇马1:1马洛卡,相比“灰头土脸”的进攻,这三个问题更需要解决
- 关于新航注册 2024-08-23
- 编辑| 中圈开球 ——【前言】—— 皇马1比1马洛卡,本赛季没有如愿取得开门红。本以为全场比赛新“三叉戟”会砍瓜切菜般的打进五六个进球,没想到最后踢的如此难看,皇马只是把最贵的东西放在了场上,只是最贵的球员却踢出了廉价的内容。安胖子哪怕晚上...